Author: CJ_Blockchain
On February 3, 2025, a model called DeepSeek-R1 quietly launched on the National Supercomputing Internet Platform.
In the following month, due to its performance directly comparable to top-tier closed-source models and training costs comparable to “cabbage prices,” it swept across the globe.
This triggered a crash in US AI stocks and marked the beginning of China’s AI “DeepSeek” era.
On March 10, 2026, Bittensor’s Subnet 3 Templar announced the completion of the largest decentralized large language model (LLM) pretraining run in history—Covenant-72B.
This is the largest decentralized large language model pretraining run in history:
- 7.2 billion parameters
- Trained on a dataset of approximately 1.1 trillion tokens
- Fully implemented through Bittensor Subnet 3 network
- Permissionless
- Over 70 independent nodes freely participating
Bittensor has entered its own DeepSeek era.
1. Templar (SN3): Paradigm Shift from Data Collection to Core Training
Templar originated from SN3 operated by Omega Labs, initially focusing on multimodal data collection and mining. As the Bittensor mechanism evolved, this subnet made a strategic leap from “data transporter” to “model creator.”
Currently, Templar positions itself as the infrastructure for global distributed large model pretraining. It aggregates heterogeneous computing power worldwide through incentive mechanisms, aiming to solve the extremely high computational costs and centralization issues in large model training. The successful delivery of Covenant-72B validates the maturity of this decentralized production model.
2. Covenant-72B: Breaking the Scale Ceiling of Decentralized Training
Covenant-72B is a milestone achievement from Templar and the largest dense architecture pretraining model in decentralized networks to date.
- Core parameters: 72 billion parameters, pretrained on the high-performance DCLM corpus.
- Performance benchmark: In foundational model evaluations, its performance is roughly on par with Meta’s Llama-2-70B.
- Instruction tuning: The fine-tuned Covenant-72B-Chat demonstrates strong competitiveness in IFEval (instruction following) and MATH (mathematical reasoning), even surpassing some closed-source models of similar scale on certain metrics.
- Inference efficiency: Achieves an extremely high throughput of 450 tokens/sec, addressing response latency issues in real-world applications.
3. SparseLoCo Algorithm: Underlying Engine for Decentralized Training
Training a 72B-scale model over the regular internet faces the biggest challenge of communication bandwidth bottlenecks between nodes. Templar made a qualitative breakthrough with the core algorithm SparseLoCo:
- Extreme compression: Only 1%-3% of core gradient components are transmitted, with data quantized to 2 bits, greatly reducing network bandwidth requirements.
- Low-frequency synchronization: Unlike traditional clusters that synchronize every step, SparseLoCo allows nodes to perform 15-250 local iterations before global synchronization.
- Error compensation: Through local gradient accumulation, it ensures model convergence accuracy even when over 97% of information is lost.
This technical approach proves that even without expensive InfiniBand clusters, top-tier intelligence can be produced relying solely on global distributed ordinary networks.
4. Industry Evaluation and Market Response
Templar’s technological achievements have attracted attention from mainstream AI circles and capital markets:
- Authoritative recognition:
Jack Clark, co-founder of Anthropic, classified Templar as the world’s largest active decentralized training network in his analysis report, noting its development speed exceeded industry expectations.
Jason Calacanis (host of All-In Podcast and well-known Silicon Valley investor) recently detailed Bittensor’s mechanism in his blog and hinted at buying opportunities.
- Institutional deployment:
Grayscale continues to increase its holdings of TAO, positioning it as a core asset in the decentralized AI track.
DCG has established Yuma, focusing on accelerating Bittensor (TAO) ecosystem development, seen as DCG’s biggest and most direct bet on decentralized AI.
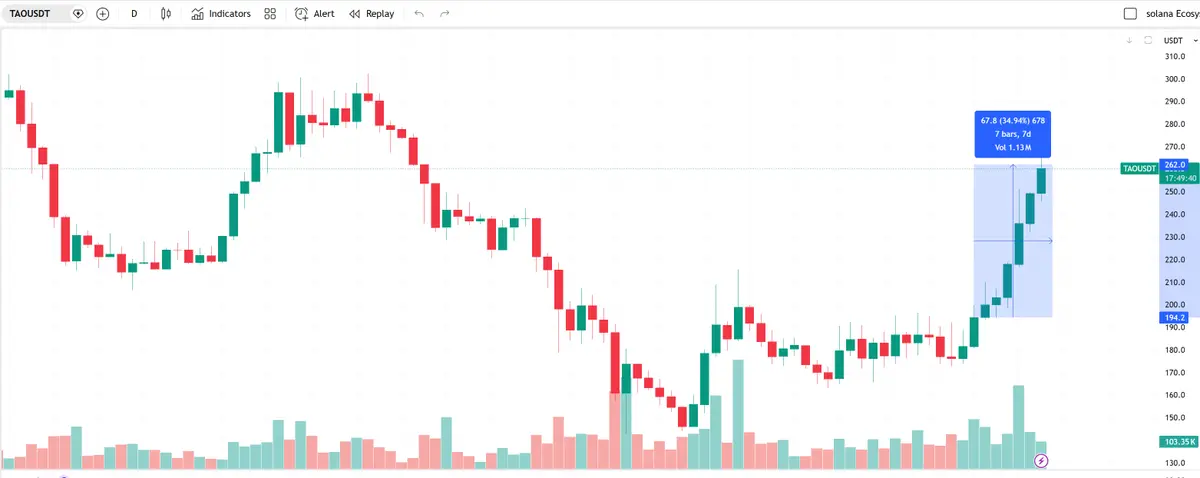
$TAO: After Templar announced the completion of the 72B model training, TAO surged over 30%, demonstrating strong performance amid BTC’s oscillations.
$Templar (SN-3): Templar rose 75% in 7 days, hailed as the current “emission capture dragon” of Bittensor. Its current market cap is only $70 million.
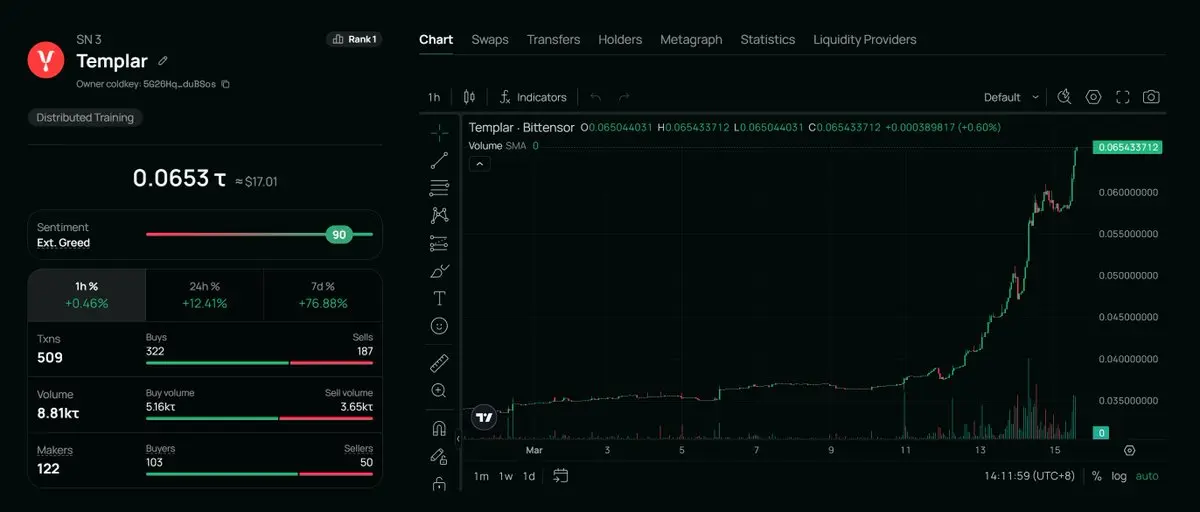
5. Subnet Investment Potential and Ecosystem Ceiling
Templar’s success opens new horizons for the Bittensor ecosystem:
- Unlocking valuation ceiling: Long-standing doubts about Bittensor being just “air incentives” are dispelled. Templar proves the protocol can produce commercially competitive productivity tools, shifting TAO’s valuation logic from “narrative-driven” to “product-driven.”
- Potential of heterogeneous computing power: With the development of “Heterogeneous SparseLoCo,” consumer-grade GPUs (like RTX 4090) could directly participate in training models with hundreds of billions of parameters, democratizing computing resources.
- Deterministic opportunity for subnets: Under the dTAO mechanism, subnets like Templar with hardcore technological barriers and the ability to continuously produce high-performance models have high long-term value.
Templar current MC=75m, FDV=350m
Compared to mainstream large model companies: OpenAI valued at $840 billion, Anthropic at $350 billion, Minimax at $45 billion.
While Templar may not directly rival these giants, in a current environment of narrative scarcity, declining attention, and skepticism towards decentralization, Templar’s emergence is undoubtedly a strong boost for decentralized AI.
Conclusion
Templar demonstrates that decentralization can do more than store data—it can produce intelligence. Covenant-72B is just the beginning. With the vertical integration of SN3 (pretraining), SN39 (computing power), and SN81 (reinforcement learning), a blockchain-based, decentralized prototype of OpenAI is already emerging.
Since its inception, the crypto industry has debunked countless narratives. While decentralized storage, computing, and networks once seemed promising, they now appear discredited. Nonetheless, some projects continue steadfastly on the path of decentralization and have achieved results.
Templar’s success is not only Bittensor’s DeepSeek moment but perhaps also the crypto industry’s DeepSeek moment.
Disclaimer: The information on this page may come from third parties and does not represent the views or opinions of Gate. The content displayed on this page is for reference only and does not constitute any financial, investment, or legal advice. Gate does not guarantee the accuracy or completeness of the information and shall not be liable for any losses arising from the use of this information. Virtual asset investments carry high risks and are subject to significant price volatility. You may lose all of your invested principal. Please fully understand the relevant risks and make prudent decisions based on your own financial situation and risk tolerance. For details, please refer to
Disclaimer.
