التداول
أساسي
العقود الآجلة
العقود الآجلة
مئات العقود تتم تسويتها بـ USDT أو BTC
الخیارات المتاحة
HOT
تداول خيارات الفانيلا على الطريقة الأوروبية
الحساب الموحد
زيادة كفاءة رأس المال إلى أقصى حد
التداول التجريبي
انطلاقة العقود الآجلة
استعد لتداول العقود الآجلة
أحداث مستقبلية
شارك في الفعاليات لربح مكافآت سخية
التداول التجريبي
استخدم الأموال الافتراضية لتجربة التداول بدون مخاطر
اكسب
إطلاق
CandyDrop
اجمع الحلوى لتحصل على توزيعات مجانية.
منصة الإطلاق
-التخزين السريع، واربح رموزًا مميزة جديدة محتملة!
HODLer Airdrop
احتفظ بـ GT واحصل على توزيعات مجانية ضخمة مجانًا
منصة الإطلاق
كن من الأوائل في الانضمام إلى مشروع التوكن الكبير القادم
نقاط Alpha
NEW
تداول الأصول على السلسلة واستمتع بمكافآت التوزيع المجاني!
نقاط العقود الآجلة
NEW
اكسب نقاط العقود الآجلة وطالب بمكافآت التوزيع المجاني
الاستثمار
الربح البسيط
اكسب فوائد من الرموز المميزة غير المستخدمة
الاستثمار التلقائي
استثمر تلقائيًا على أساس منتظم
الاستثمار المزدوج
اشترِ بسعر منخفض وبِع بسعر مرتفع لتحقيق أرباح من تقلبات الأسعار
التخزين الناعم
اكسب مكافآت مع التخزين المرن
استعارة واقتراض العملات
0 Fees
ارهن عملة رقمية واحدة لاقتراض عملة أخرى
مركز الإقراض
منصة الإقراض الشاملة
مركز ثروة VIP
إدارة الثروات المخصصة تمكّن نمو أصولك
إدارة الثروات الخاصة من
إدارة أصول مخصصة لتنمية أصولك الرقمية
الصندوق الكمي
يساعدك فريق إدارة الأصول المحترف على تحقيق الأرباح بسهولة
التكديس
قم بتخزين العملات الرقمية للحصول على أرباح في منتجات إثبات الحصة
الرافعة المالية الذكية
NEW
لا تتم التصفية القسرية قبل تاريخ الاستحقاق، مما يتيح تحقيق أرباح باستخدام الرافعة المالية دون قلق
سكّ GUSD
استخدم USDT/USDC لسكّ GUSD للحصول على عوائد بمستوى الخزانة
المزيد
BNY تقدم الودائع المرمزة للمؤسسات و'الرقميون الأصليون'
منذ 5 د
ريبل تحصل على الضوء الأخضر من FCA لتوسيع مدفوعات العملات الرقمية في المملكة المتحدة
منذ 1 س
المواضيع الرائجة
عرض المزيد25.4K درجة الشعبية
50.29K درجة الشعبية
16.6K درجة الشعبية
11.73K درجة الشعبية
99.77K درجة الشعبية
Gate Fun الساخن
عرض المزيد- 1

锦鲤
锦鲤
القيمة السوقية:$3.57Kعدد الحائزين:10.00% - القيمة السوقية:$3.58Kعدد الحائزين:10.00%
- القيمة السوقية:$3.57Kعدد الحائزين:10.00%
- القيمة السوقية:$3.69Kعدد الحائزين:20.40%
- القيمة السوقية:$3.58Kعدد الحائزين:10.00%
تثبيت
المطلعون يقولون إن DeepSeek V4 سيتفوق على Claude و ChatGPT في البرمجة، وسيتم إطلاقه خلال أسابيع
باختصار
يُقال إن DeepSeek يخطط لإطلاق نموذج V4 الخاص به حوالي منتصف فبراير، وإذا كانت الاختبارات الداخلية مؤشرًا، فيجب أن يكون عمالقة الذكاء الاصطناعي في وادي السيليكون في حالة قلق. شركة الذكاء الاصطناعي المقيمة في هانغتشو قد تستهدف إصدارًا حول 17 فبراير — بمناسبة رأس السنة القمرية، بطبيعة الحال — مع نموذج مصمم خصيصًا لمهام الترميز، وفقًا لـ The Information. يدعي أشخاص لديهم معرفة مباشرة بالمشروع أن V4 يتفوق على كل من Claude من Anthropic و GPT من OpenAI في الاختبارات الداخلية، خاصة عند التعامل مع مطالبات ترميز طويلة جدًا. بالطبع، لم يتم مشاركة أي معايير أو معلومات عن النموذج علنًا، لذلك من المستحيل التحقق مباشرة من هذه الادعاءات. لم تؤكد DeepSeek الشائعات أيضًا.
ومع ذلك، فإن مجتمع المطورين لا ينتظر كلمة رسمية. منتديات r/DeepSeek و r/LocalLLaMA على Reddit بدأت بالفعل في النشاط، المستخدمون يخزنون أرصدة API، والمتحمسون على X كانوا سريعًا في مشاركة توقعاتهم بأن V4 قد يعزز مكانة DeepSeek كالمنافس العنيد الذي يرفض اللعب وفق قواعد وادي السيليكون ذات المليارات.
لن يكون هذا هو الاضطراب الأول لـ DeepSeek. عندما أطلقت الشركة نموذج التفكير R1 في يناير 2025، أدى ذلك إلى بيع هائل بقيمة $1 تريليون في الأسواق العالمية. السبب؟ أن نموذج R1 من DeepSeek تساوى مع نموذج o1 من OpenAI في معايير الرياضيات والتفكير على الرغم من أن تكلفته المبلغ عنها كانت فقط $6 مليون للتطوير — أي أقل بنحو 68 مرة مما كانت تنفقه الشركات المنافسة. لاحقًا، وصل نموذج V3 إلى 90.2% على معيار MATH-500، متجاوزًا Claude الذي حقق 78.3%، ونسخته الأخيرة “V3.2 Speciale” حسنت أدائه أكثر.
الصورة: DeepSeek
التركيز على الترميز في V4 سيكون تحولًا استراتيجيًا. بينما ركز R1 على التفكير الخالص — المنطق، الرياضيات، الإثباتات الرسمية — فإن V4 هو نموذج هجين (للتفكير والمهام غير التفكير) يستهدف سوق المطورين المؤسساتي حيث يترجم توليد الكود عالي الدقة مباشرة إلى الإيرادات. للسيطرة على السوق، يجب أن يتفوق V4 على Claude Opus 4.5، الذي يحمل حاليًا رقم قياسي في اختبار SWE-bench Verified بنسبة 80.9%. ولكن إذا كانت إطلاقات DeepSeek السابقة دليلًا، فربما ليس من المستحيل تحقيق ذلك حتى مع جميع القيود التي قد تواجهها مختبرات الذكاء الاصطناعي الصينية. الصلصة غير السرية إذا كانت الشائعات صحيحة، فكيف يمكن لهذا المختبر الصغير أن يحقق مثل هذا الإنجاز؟ السلاح السري للشركة قد يكون موجودًا في ورقة البحث الصادرة في 1 يناير: Manifold-Constrained Hyper-Connections، أو mHC. شارك في تأليفها المؤسس ليانغ وينفينغ، وتتناول طريقة التدريب الجديدة مشكلة أساسية في توسيع قدرات النماذج اللغوية الكبيرة — كيف يمكن توسيع قدرة النموذج دون أن يصبح غير مستقر أو ينفجر أثناء التدريب. الهياكل التقليدية للذكاء الاصطناعي تجبر كل المعلومات على المرور عبر مسار ضيق واحد. يوسع mHC ذلك المسار إلى تدفقات متعددة يمكنها تبادل المعلومات دون التسبب في انهيار التدريب.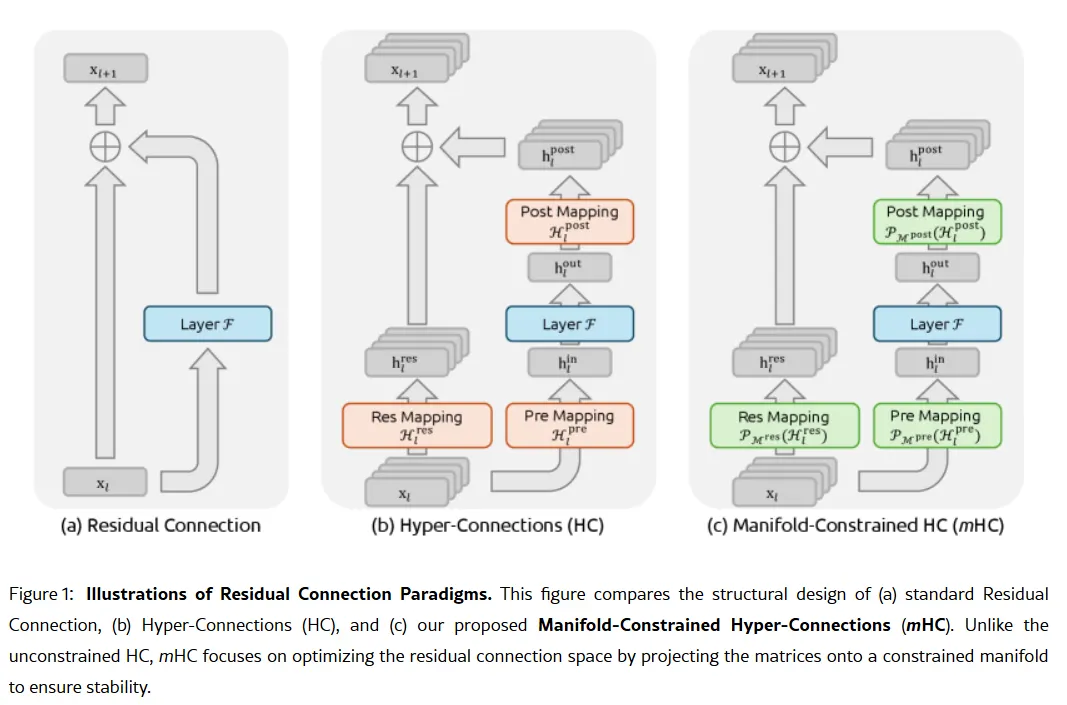
الصورة: DeepSeek
وصف وان سون، المحلل الرئيسي للذكاء الاصطناعي في شركة Counterpoint Research، تقنية mHC بأنها “اختراق مذهل” في تعليقات لـ Business Insider. وقالت إن التقنية تظهر أن DeepSeek يمكنها “تجاوز عنق الزجاجة في الحوسبة وفتح قفزات في الذكاء”، حتى مع محدودية الوصول إلى رقائق متقدمة بسبب قيود التصدير الأمريكية. لوين جاي سو، المحلل الرئيسي في Omdia، أشار إلى أن استعداد DeepSeek لنشر طرقها يدل على “ثقة جديدة في صناعة الذكاء الاصطناعي الصينية”. النهج المفتوح للمؤسسة جعله مفضلًا بين المطورين الذين يرون فيه تجسيدًا لما كانت عليه OpenAI من قبل، قبل أن تتحول إلى نماذج مغلقة وجولات جمع تبرعات بمليارات الدولارات.
ليس الجميع مقتنعين. بعض المطورين على Reddit يشتكون من أن نماذج التفكير في DeepSeek تضيع الحوسبة على مهام بسيطة، بينما يجادل النقاد بأن معايير الشركة لا تعكس الفوضى الواقعية. منشور على Medium بعنوان “DeepSeek سيء — وأنا انتهيت من التظاهر بعدم ذلك” انتشر في أبريل 2025، متهمًا النماذج بإنتاج “هراء قياسي مع أخطاء” و“مكتبات هلوسة”. كما أن DeepSeek يحمل عبءًا. المخاوف بشأن الخصوصية لطالما كانت مصدر قلق، حيث حظرت بعض الحكومات التطبيق الأصلي لـ DeepSeek. علاقات الشركة بالصين وأسئلة الرقابة على نماذجها تضيف توترًا جيوسياسيًا إلى النقاشات التقنية. ومع ذلك، فإن الزخم لا يمكن إنكاره. لقد تم اعتماد DeepSeek على نطاق واسع في آسيا، وإذا وفى V4 بوعده في الترميز، فقد يتبع ذلك اعتماد المؤسسات في الغرب.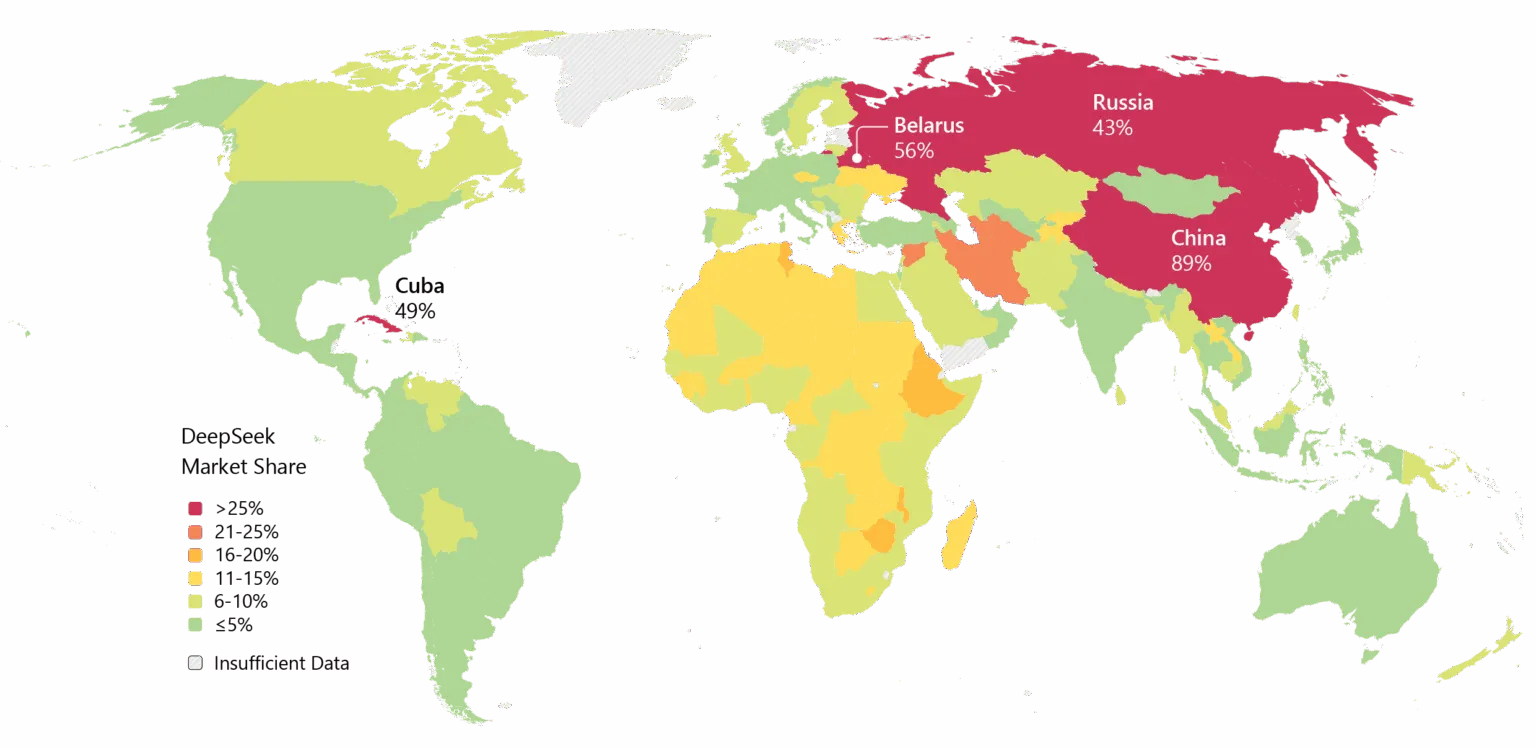
الصورة: Microsoft
هناك أيضًا التوقيت. وفقًا لـ Reuters، كانت DeepSeek تخطط أصلاً لإطلاق نموذج R2 في مايو 2025، لكنها مددت الفترة بعد أن أصبح المؤسس ليانغ غير راضٍ عن أدائه. الآن، مع استهداف V4 لشهر فبراير وR2 قد يتبع في أغسطس، تتحرك الشركة بسرعة توحي بالإلحاح — أو الثقة. وربما كلاهما.